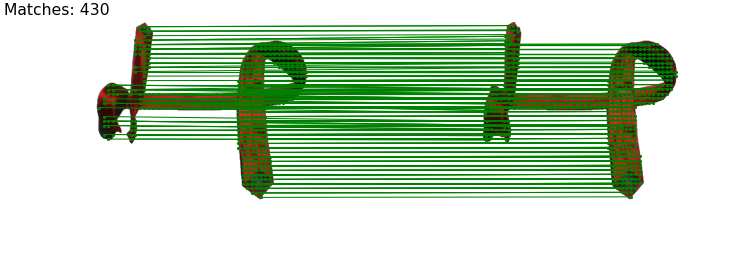
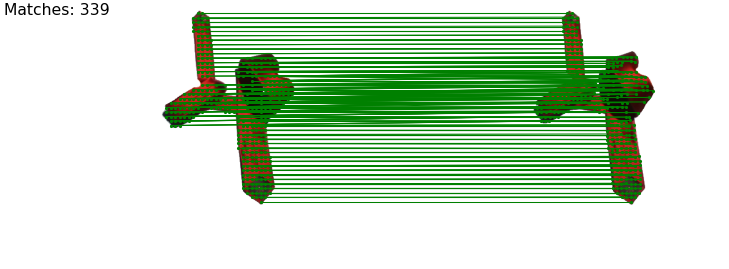
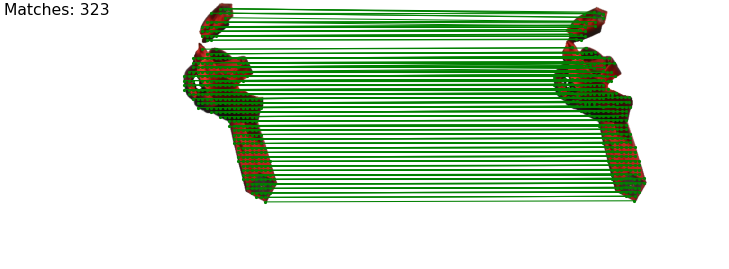
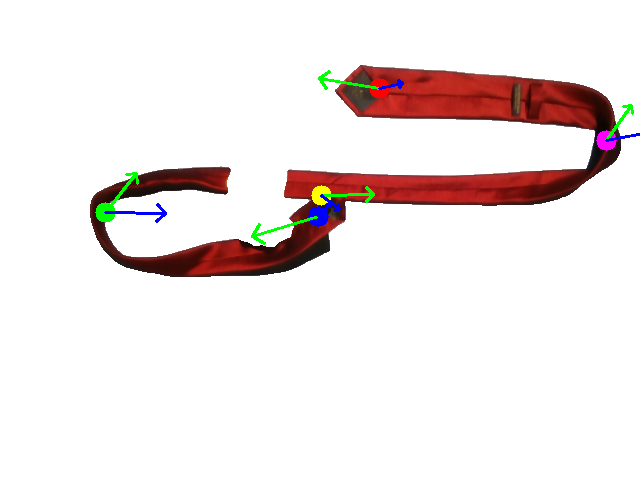
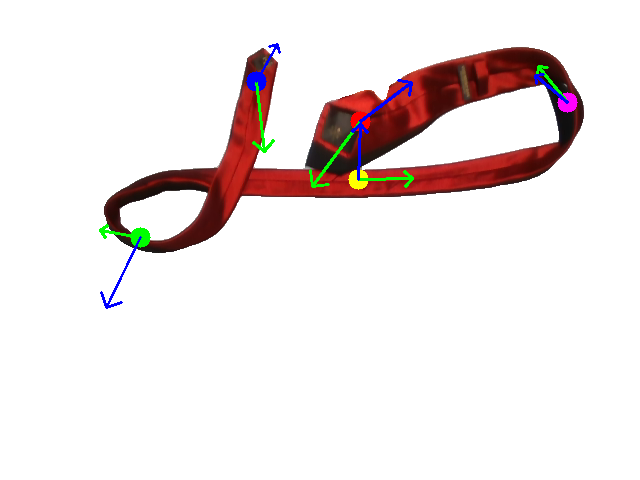
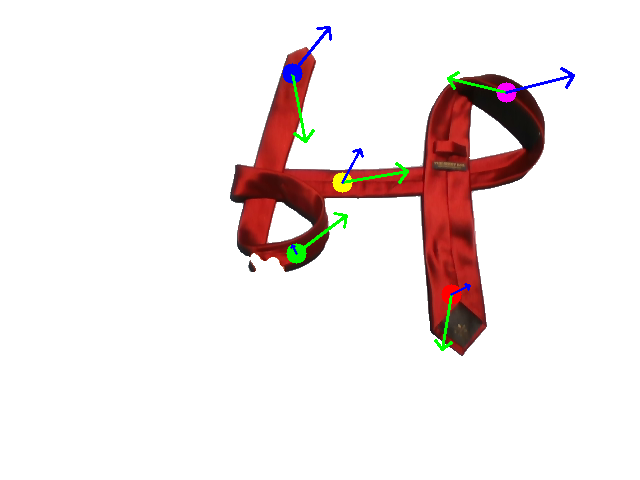
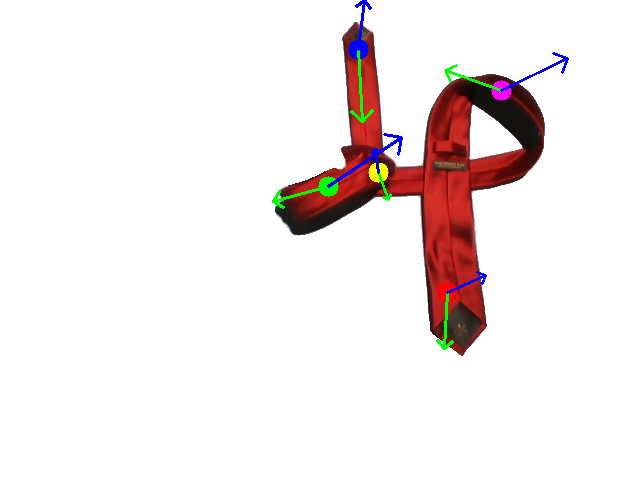
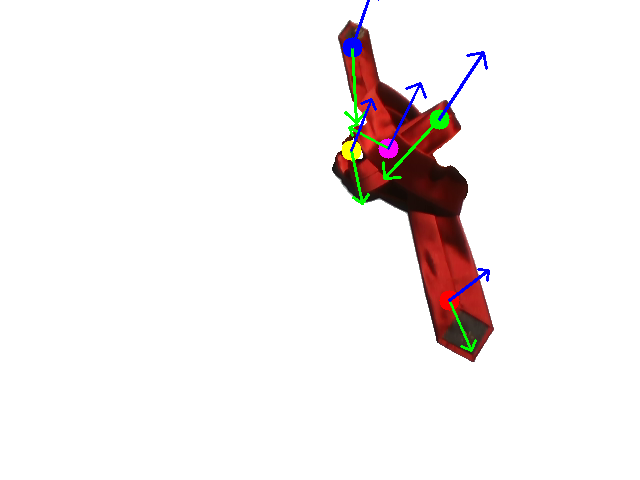
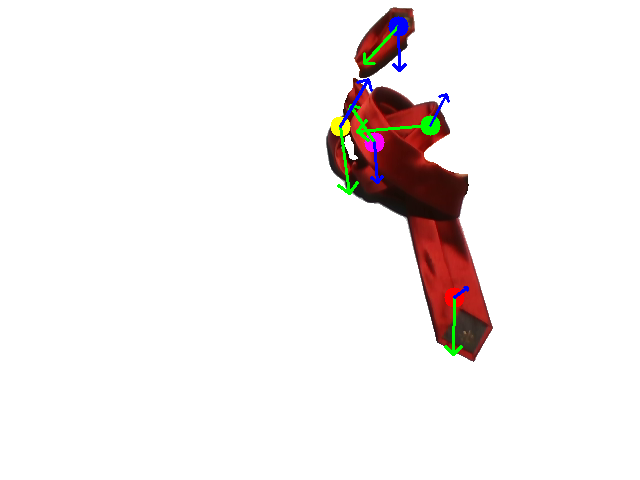
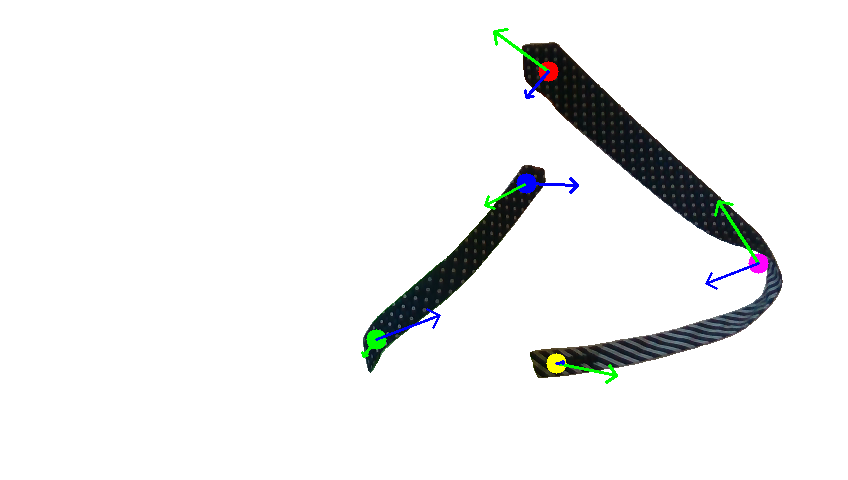
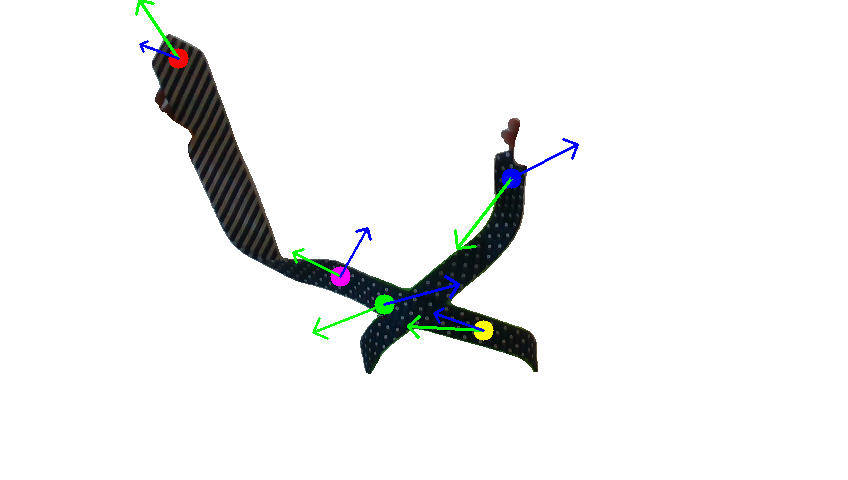
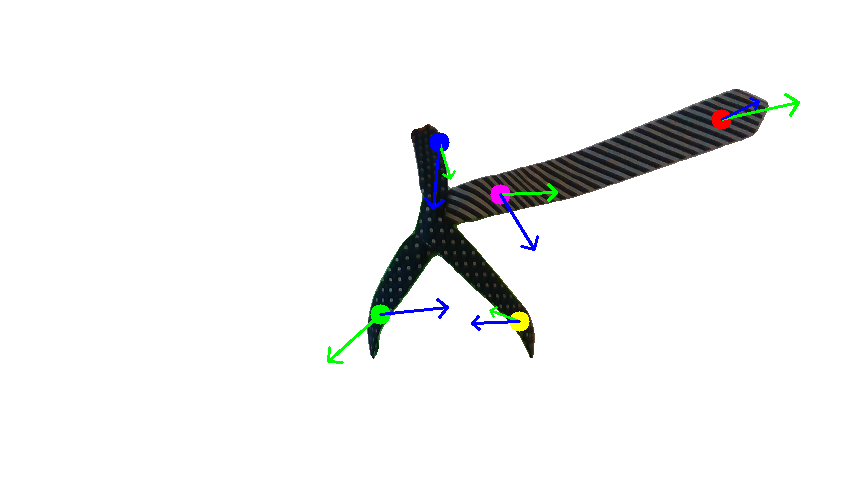
Human demonstration of the first tie-knotting task.
Abstract
The tie-knotting task is highly challenging due to the tie's high deformation and long-horizon manipulation actions. This work presents TieBot, a Real-to-Sim-to-Real learning from visual demonstration system for the robots to learn to knot a tie. We introduce the Hierarchical Feature Matching approach to estimate a sequence of tie's meshes from the demonstration video. With these estimated meshes used as subgoals, we first learn a teacher policy using privileged information. Then, we learn a student policy with point cloud observation by imitating teacher policy. Lastly, our pipeline learns a residual policy when the learned policy is applied to real-world execution, mitigating the Sim2Real gap. We demonstrate the effectiveness of TieBot in simulation and the real world. In the real-world experiment, a dual-arm robot successfully knots a tie, achieving 50% success rate among 10 trials.
Video Summary
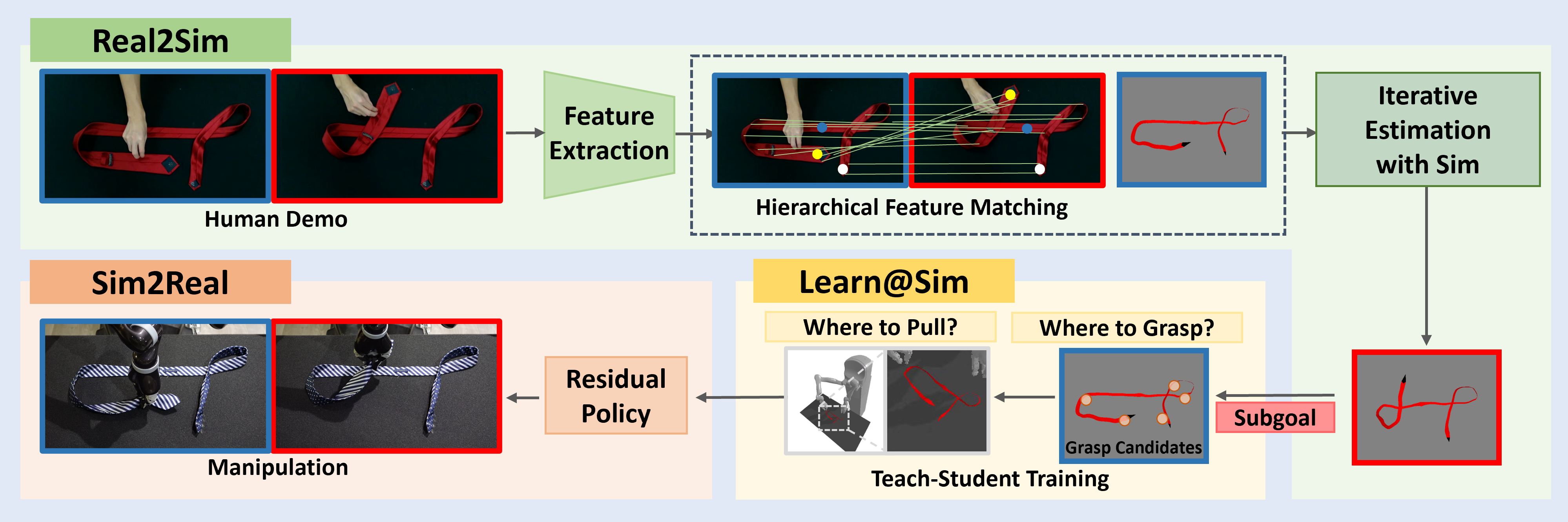
Pipeline Overview
Our pipeline first apply local feature matching and keypoints detection to estimate the mesh of the tie in the human demonstration, with a given mesh model. Then, we learn to select grasping points for robots using RL, and train a student policy to imitate the teacher policy. Finally, we learn a residual policy when deploying to real robots.
Human Demonstration
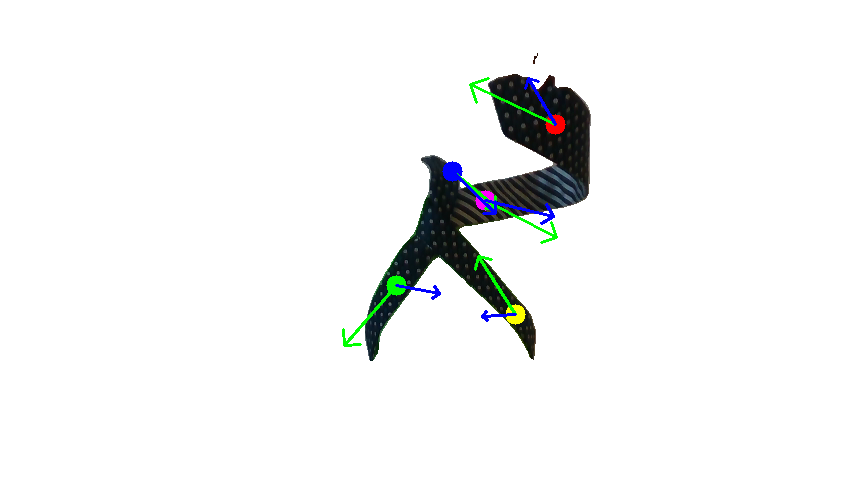
Human demonstration of the second tie-knotting task.
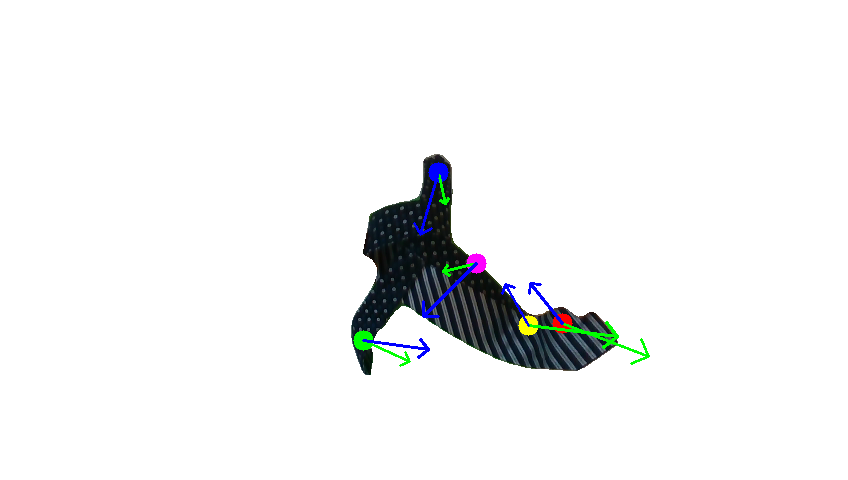
Human demonstration of the towel-folding task.